
k8s中的Service的实现
又是水一篇总结的博客……
概述
首先了解k8s的集群网络模型是很有必要的,也是这篇博客的前提。这里建议直接阅读k8s网络模型的设计文档,可以让你对我们本篇所讨论的有个大致的了解。
在k8s框架中,每个Pod和容器一样只具有临时的生命周期,一个Pod随时有可能被终止或者漂移,我们不应当期望一个容器和pod是耐用和可用的。这时候假如我们直接对一个pod进行访问,那么我们很难保证服务的高可用和动态性,因此显然不能使用Pod地址作为服务暴露端口。
因此我们需要想办法将对服务的访问进行代理转发,不依赖于pod的地址。在k8s中,通过负载均衡和VIP实现后端真实服务的自动转发、故障转移。这个负载均衡在Kubernetes中称为Service。Kubernetes的Service就是一个四层负载均衡,Kubernetes对应的还有七层负载均衡Ingress,本文仅介绍Kubernetes Service。
Kubernetes中的Deployment保证了我们不需要去管理pod的创建与销毁以及健康状态,而Service是将运行在一个或一组Pod上的网络应用程序公开为网络服务的方法。Service让我们无需去管理pod的端口与ip地址。Service 是 Kubernetes 中的一种抽象,用于将一组具有相同功能的 Pod 组合成一个逻辑单元,并通过 Service IP 对外提供访问。这个 Service IP 就是虚拟 IP,它并不属于任何一个具体的 Pod,而是由 Kubernetes 控制平面管理的。
一个常见的问题是,为什么Kubernetes通过依赖代理将入站流量转发到后端。其他方案呢?例如,是否可以配置具有多个 A 值(或 IPv6 的 AAAA的DNS记录,使用轮询域名解析?使用代理转发方式实现 Service 的原因有以下几个:
- DNS 的实现不遵守记录的 TTL 约定的历史由来已久,在记录过期后可能仍有结果缓存。
- 有些应用只做一次 DNS 查询,然后永久缓存结果。
- 即使应用程序和库进行了适当的重新解析,TTL 取值较低或为零的 DNS 记录可能会给 DNS 带来很大的压力,从而变得难以管理。
虚拟ip
在 Kubernetes 中,虚拟IP(Virtual IP,VIP)通常指的是Service IP(服务 IP)。与实际路由到固定目标的Pod IP地址不同,Service IP 实际上不是由单个主机回答的。相反,kube-proxy使用数据包处理逻辑(例如Linux的iptables)来定义虚拟 IP 地址,这些地址会按需被透明重定向。实际上,Service 的环境变量和 DNS 是根据 Service 的虚拟 IP 地址(和端口)填充的。当客户端连接到VIP时,其流量会自动传输到适当的端点。具体来说,当创建一个 Service 时,Kubernetes 会为该 Service 分配一个虚拟 IP。当集群内的其他 Pod 或外部客户端通过这个虚拟 IP 访问该 Service 时,Kubernetes 的 Service 控制器会将请求转发到该 Service 关联的一组 Pod 中的一个或多个实际后端 Pod。这样就实现了服务的负载均衡和高可用性。
Kubernetes 的主要哲学之一是,你不应需要在完全不是你的问题的情况下面对可能导致你的操作失败的情形。对于Service资源的设计,如果你选择的IP可能与其他人的选择冲突,就不应该让你自己选择IP地址。这是一种失败隔离。
为了确保没有任何两个Service会发生冲突。 Kubernetes通过为API服务器配置的service-cluster-ip-rangeCIDR范围内为每个 Service 分配自己的IP地址来避免冲突。
虚拟 IP 通常是一个 ClusterIP,它只能在集群内部访问,在集群外部使用ip栈协议工具是无法访问到这个IP的。除了 ClusterIP,Kubernetes 还支持其他类型的 Service,如 NodePort、LoadBalancer 和 ExternalName,它们可以为 Service 提供不同的访问方式和暴露方式。
iptable和ipvs
在k8s集群中,kube-proxy是 Kubernetes 集群中的一个关键组件,主要负责实现服务的负载均衡和网络流量的转发也就是Service的功能。kube-proxy 监听 Kubernetes API Server 中的服务对象,并根据服务定义创建对应的负载均衡规则。它为每个服务创建一个虚拟 IP 地址,并将流量转发到后端的 Pod 上。
kube-proxy主要通过代理来实现Service,kube-proxy现在的主要代理模式有三种:
- iptables 运行在用户空间的应用软件,通过控制Linux内核netfilter模块,来管理网络数据包的处理和转发。
- ipvs 专门用于负载均衡的Linux内核功能
- kernelspace 专用于windows的代理,就不做赘述了。
ipvs 和 iptables 都是基于netfilter的,那么 ipvs 模式和 iptables 模式之间有哪些差异呢?
iptables
iptables简介
iptables 是 Linux 防火墙工作在用户空间的管理工具,是 netfilter/iptablesIP 信息包过滤系统是一部分,用来设置、维护和检查 Linux 内核的 IP 数据包过滤规则。
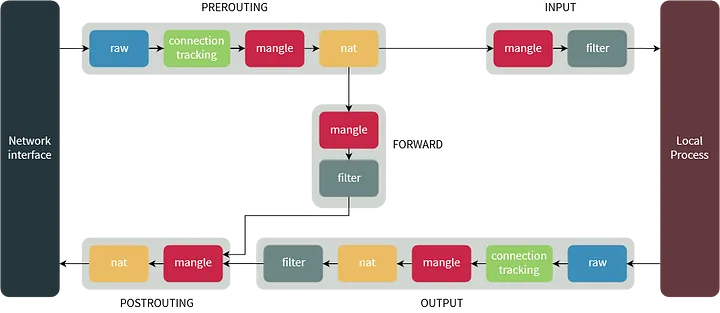
iptables简单来说由三表五链组成。iptables的结构是由表(tables)组成,而tables是由链组成,链又是由具体的规则组成。因此我们在编写iptables规则时,要先指定表,再指定链。tables的作用是区分不同功能的规则,并且存储这些规则。

三张表介绍:
filter 负责过滤数据包,包括的规则链有:input,output和forward
nat 用于网络地址转换(IP、端口),包括的规则链有:prerouting,postrouting 和 output
mangle 主要应用在修改数据包、流量整形、给数据包打标识,默认的规则链有:INPUT,OUTPUT、 forward,POSTROUTING,PREROUTING
优先级:mangle > nat > filter
五条链:
input 处理输入数据包
output 处理输出数据包
forward 处理转发数据包
prerouting 用于目标地址转换(DNAT)
postrouting 用于源地址转换(SNAT)
一个IP数据包经过iptables的流程如下所示
常见选项:
1 | -t<表>:指定要操纵的表; |
下面给出一些常见的iptables的命令
1 | iptables -t 表名 <-A/I/D/R> 规则链名 [规则号] <-i/o 网卡名> -p 协议名 <-s 源IP/源子网> --sport 源端口 <-d 目标IP/目标子网> --dport 目标端口 -j 动作 |
iptables模模式
在这种模式下,kube-proxy 监视 Kubernetes 控制平面,获知对 Service 和 EndpointSlice 对象的添加和删除操作。 对于每个 Service,kube-proxy 会添加 iptables 规则,这些规则捕获流向 Service 的 clusterIP 和 port 的流量, 并将这些流量重定向到 Service 后端集合中的其中之一。 对于每个端点,它会添加指向一个特定后端 Pod 的 iptables 规则。
默认情况下,iptables 模式下的 kube-proxy 会随机选择一个后端。
使用 iptables 处理流量的系统开销较低,因为流量由 Linux netfilter 处理, 无需在用户空间和内核空间之间切换。这种方案也更为可靠。
如果 kube-proxy 以 iptables 模式运行,并且它选择的第一个 Pod 没有响应, 那么连接会失败。这与用户空间模式不同: 在后者这种情况下,kube-proxy 会检测到与第一个 Pod 的连接失败, 并会自动用不同的后端 Pod 重试。当然可以使用 Pod 就绪探针来验证后端 Pod 是否健康。 这样可以避免 kube-proxy 将流量发送到已知失败的 Pod 上。
这里我们简述一下
ipvs
ipvs (IP Virtual Server) 实现了传输层负载均衡,也就是我们常说的4层LAN交换。IPVS 可以工作在四层(传输层)和七层(应用层)之间,支持 TCP、UDP、SCTP 等不同的传输层协议,并可以进行基于连接、基于数据包等级别的负载均衡。。作为 Linux 内核的一部分,IPVS(IP Virtual Server)用于实现基于 IP 的负载均衡。它能够将传入的 IP 数据包根据一定的调度算法(如轮询、加权轮询、最小连接数等)分发到多个后端服务器上,从而实现了负载均衡和高可用性。ipvs运行在主机上,在真实服务器集群前充当负载均衡器。ipvs可以将基于TCP和UDP的服务请求转发到真实服务器上,并使真实服务器的服务在单个 IP 地址上显示为虚拟服务。
ipvs 会使用 iptables 进行包过滤、SNAT、masquared(伪装)。具体来说,ipvs 将使用ipset来存储需要DROP或masquared的流量的源或目标地址,以确保 iptables 规则的数量是恒定的,这样我们就不需要关心我们有多少服务了
在 ipvs 模式下,kube-proxy 监视 Kubernetes Service 和 EndpointSlice,然后调用 netlink 接口创建 IPVS 规则,并定期与 Kubernetes Service 和 EndpointSlice 同步 IPVS 规则。该控制回路确保 IPVS 状态与期望的状态保持一致。访问 Service 时,IPVS 会将流量导向到某一个后端 Pod。
IPVS 代理模式基于 netfilter 回调函数,类似于 iptables 模式, 但它使用哈希表作为底层数据结构,在内核空间中生效。 这意味着 IPVS 模式下的 kube-proxy 比 iptables 模式下的 kube-proxy 重定向流量的延迟更低,同步代理规则时性能也更好。 与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
IPVS 为将流量均衡到后端 Pod 提供了更多选择:
rr(轮询):流量被平均分发给后端服务器。
wrr(加权轮询):流量基于服务器的权重被路由到后端服务器。 高权重的服务器接收新的连接并处理比低权重服务器更多的请求。
lc(最少连接):将更多流量分配给活跃连接数较少的服务器。
wlc(加权最少连接):将更多流量按照服务器权重分配给连接数较少的服务器,即基于连接数除以权重。
lblc(基于地域的最少连接):如果服务器未超载且可用,则针对相同 IP 地址的流量被发送到同一后端服务器; 否则,流量被发送到连接较少的服务器,并在未来的流量分配中保持这一分配决定。
lblcr(带副本的基于地域的最少连接):针对相同 IP 地址的流量被发送到连接数最少的服务器。 如果所有后端服务器都超载,则选择连接较少的服务器并将其添加到目标集中。 如果目标集在指定时间内未发生变化,则从此集合中移除负载最高的服务器,以避免副本的负载过高。
sh(源哈希):通过查找基于源 IP 地址的静态分配哈希表,将流量发送到某后端服务器。
dh(目标哈希):通过查找基于目标地址的静态分配哈希表,将流量发送到某后端服务器。
sed(最短预期延迟):流量被转发到具有最短预期延迟的后端服务器。 如果流量被发送给服务器,预期延迟为 (C + 1) / U,其中 C 是服务器上的连接数, U 是服务器的固定服务速率(权重)。
nq(永不排队):流量被发送到一台空闲服务器(如果有的话),而不是等待一台快速服务器; 如果所有服务器都忙碌,算法将退回到 sed 行为。
但是由于是新版本特性,ipvs也存在很多问题,还需要改进。相比之下iptables更为可靠。
参考文字:

