作者 青鸟
最近的实习中,涉及到有状态容器的处理。在技术探索的过程中遇到了很多问题,值得写一篇博客来简单记录一下sealos中的的devbox项目对k8s有状态容器的解决的方案。解决方案或许存在些许问题,但是在特定的需求场景下也具有一定的参考意义。
特别感谢一下曾哥和杨哥。没有他们的指导就不会有这段收获满满的实习经历和技术收获。
遇到的问题
对于有状态容器是否应该编排在k8s中,一直是存在争议的。k8s原生对于有状态容器的管理主要为stateful set(之后都简写为sts) sts为每个pod提供了headless service的访问方式,独立的ip与存储,滚动更新等,但是仍然存在很多的问题。关于sts的策略和存在的问题以及社区提出的一些方法需要长篇大论去描述,因此之后也会单独写一篇关于sts与有状态容器的博客去详细说明,在此就不一一赘述了。这里就举一个最简单的例子来描述 sts的缺陷。在node节点宕机后,depolyment等控制器可以完成pod漂移来保证服务的可用性(虽然对于不同类型的pv,pod漂移时间不一致,比如外置块存储iSCSI SAN,默认attach的6分种失联后,才会deattch掉故障节点,对漂移速度影响较大,但是是可以完成pod的漂移来保证有状态容器的高可用的)。对于sts来说,节点宕机的时候是不能pod漂移的,不能排除pod的失联是不是由于集群脑裂等问题造成,如果自动完成漂移可能会造成数据写入冲突,这对于强一致性的数据来说是不可接受的,比如数据库等。因此,k8s的处理是需要手动恢复pod。这对服务的高可用来说是需要考量的一件事情。当然这都是可以处理的,腾讯云提供了statefulsetplus去解决这种问题。类似的问题还有很多,但是没有万能的银弹去解决有状态容器的问题,都需要特定的场景下,提供对应的解决办法。这里有一篇对于有状态容器解析的很好的文章,可以提供些思考揭秘有状态服务上 Kubernetes 的核心技术。
那么sealos中的devbox项目的使用场景是什么呢。devbox的初衷是云环境开发,可以在本地vscode安装一个插件,之后所有的资源使用的都是云环境的容器,在完成开发后可以快速上线到在线环境。对场景分析后我们可以知道,devbox对io需求不是很大,只需要能在用户可以接受的延迟即可。需要做的是如何将pod容器提供给本地访问(这不是本文所需要介绍的重点,目前的实现是通过在镜像中预先安装ssh,通过service的noeport方式提供对外的ssh隧道连接。emmm,但是使用nodeport的方式终究是有很多限制的,后续可能会使用wstunnel隧道来优化链接,但这都是后话了)。所以我们需要关注的在于容器中的文件怎么保存,怎么在容器oom或者遇到了其他崩溃错误之后能够快速被重新拉起,或者在节点宕机的时候完成pod漂移,并且在这个过程中对于用户来说可以无感知的保存文件操作记录,这对文件的一致性提出了更高的要求。
技术调研
根据技术调研,k8s中有个特性门控为checkpoint,即容器检查点,可以将容器状态保存下来,并恢复,这个方案有个好处,可以连容器的线程一同保存,可以让在调试过程中意外中断的进程得以恢复,比如在压测的时候,容器崩溃时迅速恢复到原先的状态,可以快速复现与定位问题。但是经过调研和测试,目前虽然k8s控制器对checkpoint提供了支持,可以快速在kubelet和apiserver中开启checkpoint,但是底层的容器运行却对这一特性缺乏一些相应的支持,比如containerd虽然支持了checkpoint的导出,但是对于相应的恢复还没有完善。在调研了几款容器运行时后,只有k8s官方的crio提供了完善的支持,但是对于更换一种不熟悉的容器运行时作为底层显然是不合适的,于是乎这条技术路线只能在以后相应的支持完善后再予以讨论。
另一种方式是可以联想到docker中的commit操作,commit可以将新的snapshot导出到原来的镜像之上,将新的文件的变化以新的overlay的格式给存储到镜像中,只需要新起一个pod就可以马上这个容器了。对于镜像存储的计费可以使用s3去存储,s3的存储计费是有着成熟的解决方案的。那么有状态容器的保存操作就可以简化为在pod删除或者异常的时候去做镜像的commit(commit的实现可以直接调用nerdctl的sdk,写起来也很快)。那么相应的问题就转换为了怎么去监听pod的状态与事件的并做相应的commit以及控制策略。devbox中的解决方案是cri-shim,本质是自实现的一个k8s CRI plugin。
技术方案原理
容器运行时
首先我们需要知道的是容器本质上就是一个特殊的进程,通过 Namespace 实现资源(网络、文件系统等)隔离,通过 Cgroups 实现资源(CPU、内存)限制,让我们使用起来就感觉像在操作虚拟机一样,但其和虚拟机有本质上的区别,那就是容器和宿主机是共享同一个内核的。为了将我们的应用进程运行在容器中,当然就需要有一些方便的接口或者命令去调用 Linux 的系统功能来实现,而容器运行时就是用来运行和管理容器进程、镜像的工具。
根据容器运行时提供的功能,我们可以将容器运行时分为低层运行时和高层运行时。低层运行时主要负责与宿主机操作系统打交道,根据指定的容器镜像在宿主机上运行容器进程,并对容器的整个生命周期进行管理,也就是负责设置容器 Namespace、Cgroups 等基础操作的组件,比如runc、runv等。 高层运行时主要负责容器的生命周期管理、镜像管理、网络管理和存储管理等工作,为容器的运行做准备。主流的高层运行时包括 Containerd、CRI-O、kata等。高层运行时与低层运行时各司其职,容器运行时一般先由高层运行时将容器镜像下载下来,并解压转换为容器运行需要的操作系统文件,再由低层运行时启动和管理容器。
CRI
kubelet调用CRI去创建容器的顺序如下所示:
- Kubelet 通过 CRI runtime service API 调用 cri plugin 创建 pod
- cri 通过 CNI 创建 pod 的网络配置和 namespace
- cri 使用 containerd 创建并启动 pause container (sandbox container) 并且把这个 container 置于 pod 的 cgroups/namespace
- Kubelet 接着通过 CRI image service API 调用 cri plugin, 获取容器镜像 cri 通过 containerd 获取容器镜像
- Kubelet 通过 CRI runtime service API 调用 cri, 在 pod 的空间使用拉取的镜像启动容器
- cri 通过 containerd 创建/启动 应用容器, 并且把 container 置于 pod 的 cgroups/namespace. Pod 完成启动.
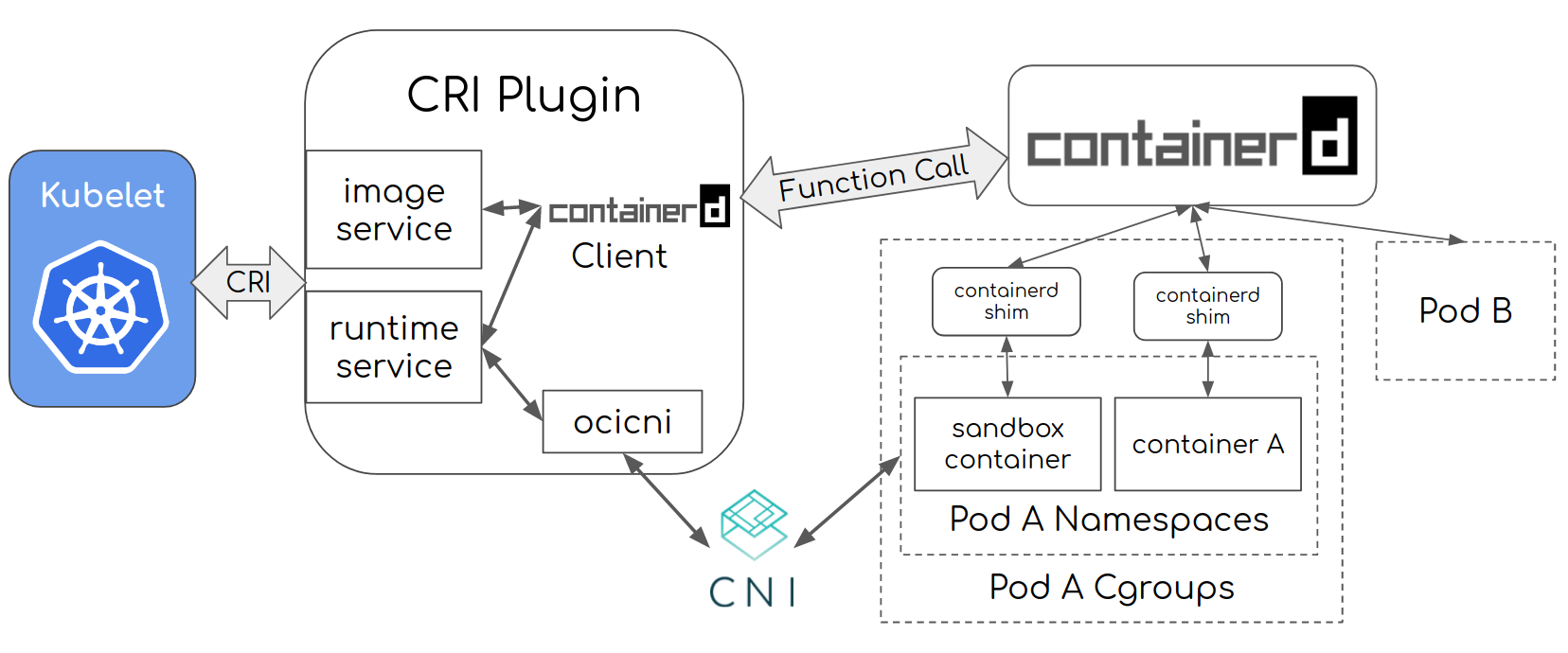
其中的CRI Plugin部分可定制化部分包括 runtime service 和 image service两部分。而runtime service便是cri-shim基于的plugin,我们可以对CRI Plugin定制化开发,由于k8s最小的操作单位为pod,cri-shim可以让我们在底层完成一些上层无法进行的操作。我们只需要按照k8s的规范,实现对应的grpc接口的proto即可,参考官方给出的即可api.proto。定制化开发的实现也可以参考cri-shim项目的实现,项目中实现了commit、push等操作,可以作为实现参考。
通过cri-shim,我们便可以在监听到有状态容器的删除的时候,将容器commit成镜像做一个状态保存。如果容器意外退出,也可以做commit保存,并通过controller实现有状态pod的自愈。当然了这种方式的commit也是有缺陷的,比如node节点宕机的时候,便无法实现pod漂移,只能等待节点痊愈后,才能恢复状态服务,对于devbox一期工程来说,这也是能接受的一种实现。
如果文章有错误或者不足之处,欢迎批评指正。
参考文章