
简单的搜索引擎原理
作者 青鸟
简单介绍一种实现搜索引擎的思路
布隆过滤器(Bloom Filter)
它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
常见的储存数据的方式是集合、链表、树这种在数组的基础上构建而成的数据结构。但是这一类数据结构的查询元素的效率会随着空间储存的增长而随之变慢。这时候,我们引入一种新的储存方式,散列表 (也就是哈希表)。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。这就是布隆过滤器的基本思想。
存入过程:
布隆过滤器上面说了,就是一个二进制数据的集合。当一个数据加入这个集合时,经历如下洗礼:
通过K个哈希函数计算该数据,返回K个计算出的hash值
这些K个hash值映射到对应的K个二进制的数组下标
将K个下标对应的二进制数据改成1。
布隆过滤器主要作用就是查询一个数据,在不在这个二进制的集合中,查询过程如下:
通过K个哈希函数计算该数据,对应计算出的K个hash值
通过hash值找到对应的二进制的数组下标
判断:如果存在一处位置的二进制数据是0,那么该数据不存在。如果都是1,该数据存在集合中。
看到这里,大家应该可以看出,如果布隆过滤器返回0,那么数据一定是没有索引过的,然而如果返回1,那也不能说数据一定就已经被索引过。在搜索过程中使用布隆过滤器可以使得很多没有命中的搜索提前返回来提高效率。
布隆过滤器的误判率主要是由对应的hash函数决定的,而hash函数又是由内存所决定的。
布隆过滤器在搜索引擎中的主要作用是url去重。可以快速并且非常节省内存地实现网页的判重。
倒排索引
基本概念
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
简单来说:
在没有搜索引擎时,我们是直接输入一个网址,然后获取网站内容,这时我们的行为是:
document -> to -> words
通过文章,获取里面的单词,此谓正向索引,forward index.
后来,我们希望能够输入一个单词,找到含有这个单词,或者和这个单词有关系的文章:
word -> to -> documents
这就是倒排序索引
倒排列表用来记录有哪些文档包含了某个单词。一般在文档集合里会有很多文档包含某个单词,每个文档会记录文档编号(DocID),单词在这个文档中出现的次数(TF)及单词在文档中哪些位置出现过等信息,这样与一个文档相关的信息被称做倒排索引项(Posting),包含这个单词的一系列倒排索引项形成了列表结构,这就是某个单词对应的倒排列表。在文档集合中出现过的所有单词及其对应的倒排列表组成了倒排索引。
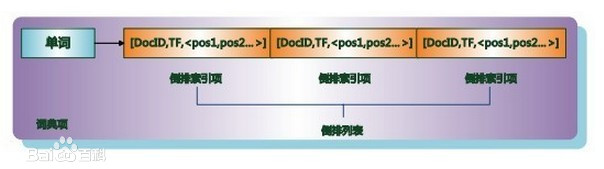
在实际的搜索引擎系统中,并不存储倒排索引项中的实际文档编号,而是代之以文档编号差值(D-Gap)。文档编号差值是倒排列表中相邻的两个倒排索引项文档编号的差值,一般在索引构建过程中,可以保证倒排列表中后面出现的文档编号大于之前出现的文档编号,所以文档编号差值总是大于0的整数。如图2所示的例子中,原始的 3个文档编号分别是187、196和199,通过编号差值计算,在实际存储的时候就转化成了:187、9、3。之所以要对文档编号进行差值计算,主要原因是为了更好地对数据进行压缩,原始文档编号一般都是大数值,通过差值计算,就有效地将大数值转换为了小数值,而这有助于增加数据的压缩率。
现代搜索引擎的索引都是基于倒排索引。相比“签名文件”、“后缀树”等索引结构,“倒排索引”是实现单词到文档映射关系的最佳实现方式和最有效的索引结构。
实现方法
分析完网页后,我们得到了一篇文章,对文章分词。
- 将文档分析成单词term标记,
- 使用hash去重单词term
- 对单词生成倒排列表
这便简单的生成了一个倒排索引。之后便能够由查询词快速(时间复杂度O(1))找到包含这个查询词的网页了
搜索引擎的简单搭建
搜集网页的信息并处理对应关系
我们使用广度优先算法来搜集网页的信息。整个互联网可以看作是数据结构中的有向图,把每个页面看作一个顶点,如果某个页面中包含另外一个页面的链接,那我们就在两个顶点之间连一条有向边。先找一些权重比较高的链接,作为种子网页链接,放入队列中。爬虫按照广度优先的策略,不停的从队列中取出链接,然后爬取相应的网页,解析出网页里包含的其他网页链接,再将解析出来的链接添加到队列中,以此来遍历整个互联网。
我们使用布隆过滤器来对得到的网页链接判重,以此优化速度。
网页编号实际上就是给每个网页分配一个唯一的ID,方便我们后续对网页进行分析、索引。
我们给网页的每一个链接分配一个编号。我们维护一个中心的计数器,每爬取到一个网页之后,就从计数器中拿一个号码,分配给这个网页,然后计数器加一。在存储网页的同时,我们将网页链接跟编号之前的对应关系,存储在另一个docid文件中。
接下来我们分析网页中的内容。
首先我们抽取网页的基本信息。第一步:去掉JavaScript代码、CSS格式以及下拉框中的内容。也就是,,这三组标签之间的内容。可以利用AC自动机实现。第二步:去掉所有HTML标签。可以通过字符串匹配算法来实现。
之后,我们对得到文本进行分词。分词我们使用比较简单的思路:使用基于字典和规则的分词方法。我们可以直接从网上下载别人整理好的字典(词库)、我们采用最长匹配规则,来对文本进行分词;我们可以将词库中的单词,构建成Trie树结构,然后拿网页文本在Trie树中匹配。每个网页的文本信息在分词完成之后,我们都得到一组单词列表。然后对每个单词分配编号。用一个散列表来维护得到的单词和编号的对应关系,也就是termid表
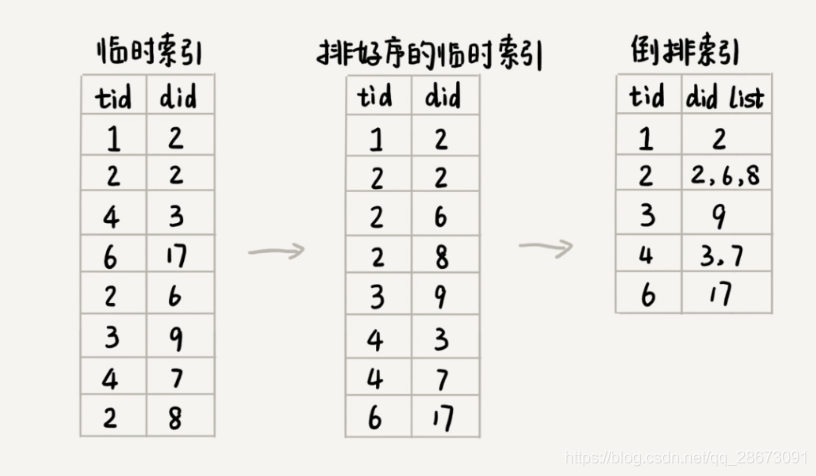
我们先对临时索引文件,按照单词编号的大小进行排序。临时索引文件很大,所以一般基于内存的排序算法就没法处理这个问题了。我们可以用归并排序的处理思想,将其分割成多个小文件,先对每个小文件独立排序,最后再合并在一起。临时索引文件排序完成之后,相同的单词就被排列到了一起,我们只需要顺序地遍历排好序的临时索引文件,就能将每个单词对应的网页编号列表找出来,由于一个单词可以对赢多个网页,我们不妨让一个单词对应一个集合。然后把它们存储到倒排索引文件index中。此时的index文件中储存了所有单词所出现的对应文章的集合。为了帮助我们快速地查找某个单词编号在倒排索引中存储的位置,我们建立一个从倒排索引中读取单词编号对应的网页编号列表term_offset表。列表里面存的是在倒排序文件中对应的偏离位置,以此来压缩数据
查询
我们需要用到上述中的四个文件:docid文件、termid表、index、term_offset表。
我们拿到用户的搜索框文本后,先进性切词处理。假设得到了n个单词。
我们拿着这n个单词从termid表中得到单词对应的n个编号
我们拿着这n个编号,从去term_offset表中查询得到n个在倒排序索引中的偏移位置。
我们通过这n个偏移位置从index中得到每一个单词所对应的网页编号集合。
我们针对这n个集合。统计每个网页编号出现的次数。具体实现,我们可以借助散列表来进行统计。统计得到的结果,我们按照出现次数的多少,从小到大排序。出现次数越多,说明包含越多的用户查询单词。
经过这一系列查询,我们就得到了一组排好序的网页编号。我们拿着网页编号,去docid文件中查找对应的网页链接,分页显示给用户就可以了。
这样子,我们就实现了一个简单的搜索引擎。
参考文章:



