
Go语言下的并发编程
作者 青鸟
go语言的高并发一直是go的特色之一。但是网上大部分文章侧重于如何使用,而对于其原理往往跳过。同时网上的大部分文章对于并发编程的一些概念往往存在很多错误,因此特地写一篇博客记录一下。
并发编程的概念
深入理解进程和线程
进程的概念:在百度百科中,进程给出的概念是操作系统中运行的程序。通俗的理解上,我们可以认为进程为操作系统中一个复杂的基本工作单位,是系统进行资源分配和调度的基本单位。每一个进程都有独立的堆栈空间,互相之间不影响,因此我们可以认为进程之间是隔离的。
进程的空间模型:
- 栈区:由编译器自动分配和释放,存放函数的参数值(形参)、局部变量(int a ;还有指针变量)等,其操作方式类似于数据结构中的栈,先进后出。
- 堆区:一般由程序员分配和释放,若程序员不释放,可能会造成内存泄漏,程序结束的时候可能由操作系统回收,注意它与数据结构中的堆是两回事,分配方式类似于链表。
- 全局区(静态区):全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域(.data),未初始化的全局变量和未初始化的静态变量在相邻的另一块区域(.bss),程序结束后系统释放。
- 文字常量区:常量字符串放在这里,程序结束后有系统释放。
- 程序代码区(.text):存放函数体的二进制代码。
线程的概念:线程是轻量级的进程。进程由操作系统来管理而线程由进程来管理。不同进程之间的地址空间是隔离的,但是不同线程之间的地址空间是共享的。一般来说,一个进程通常会有一个主线程,进程负责向内核申请线程运行所需要的资源和环境,而线程才是真正执行程序的单位。
进程是资源(CPU、内存等)分配的基本单位,线程是CPU调度和分配的基本单位(程序执行的最小单位)。线程是进程的一个执行流,进程其实是不能用来运行代码的,真正运行代码的是进程里的线程。
进程更倾向于从操作系统申请资源,并对这些资源进行统一的管理,提供一个良好的运行环境。线程则更注重利用已经分配好的资源运行程序。也就是说,实际上在 CPU 上调度执行的并不是进程而是线程。大多数操作系统对于多线程的实现都是在「用户态」下,且线程中维护的必要信息会较进程少很多。这就造成了线程是比进程更轻量级的。如果不可避免的发生频繁和切换操作,那么很明显线程在这种场景下会更具优势。
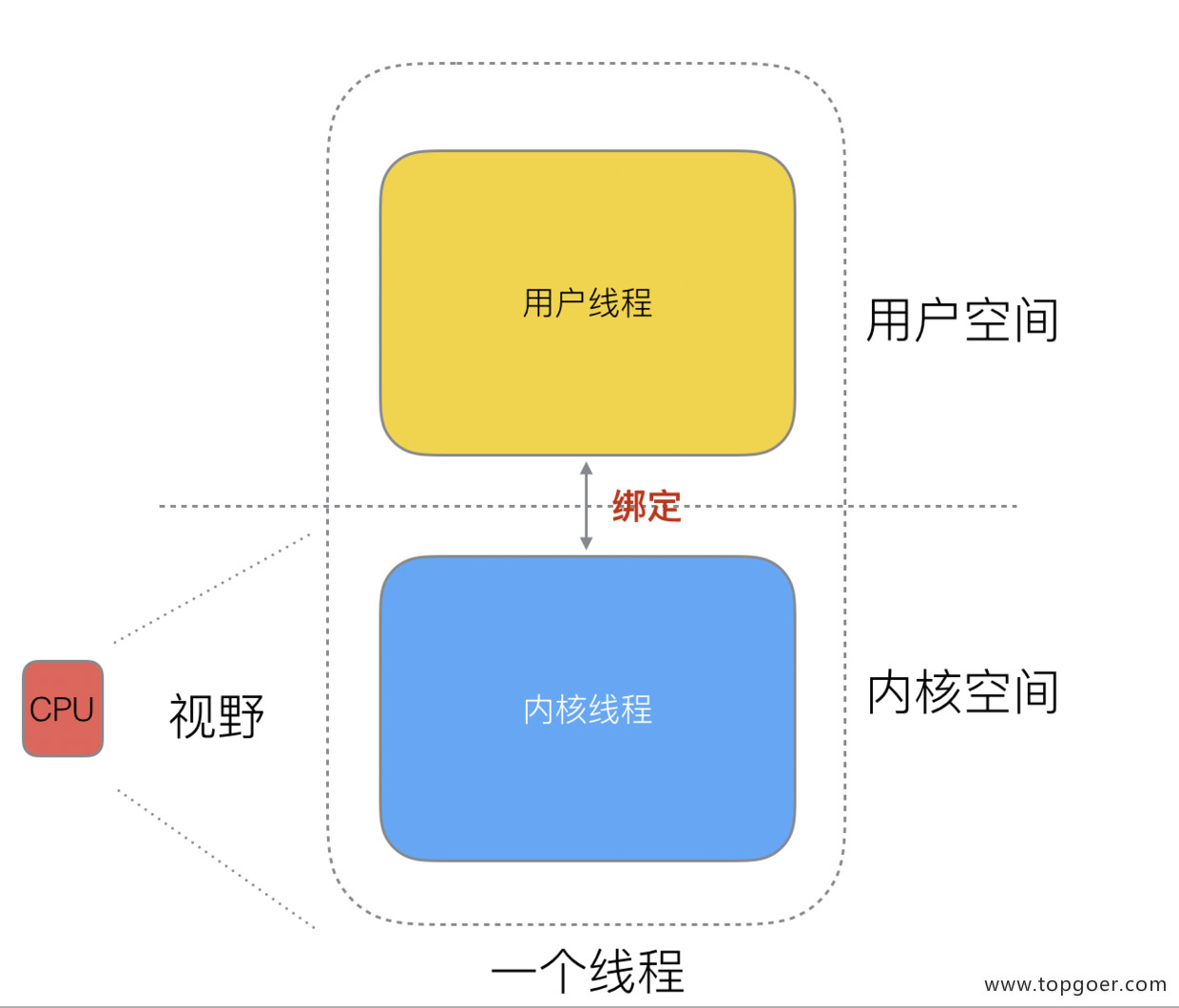
用户线程和内核线程的区别
用户线程:指不需要内核支持而在用户程序中实现的线程,其不依赖于操作系统核心,应用进程利用线程库提供创建、同步、调度和管理线程的函数来控制用户线程。不需要用户态/核心态切换,速度快,操作系统内核不知道多线程的存在,因此一个线程阻塞将使得整个进程(包括它的所有线程)阻塞。由于这里的处理器时间片分配是以进程为基本单位,所以每个线程执行的时间相对减少。
内核线程:由操作系统内核创建和撤销。内核维护进程及线程的上下文信息以及线程切换。一个内核线程由于I/O操作而阻塞,不会影响其它线程的运行。Windows NT和2000/XP支持内核线程。
并行和并发
- 并行就是利用计算机的多核优势,几个进程在用一个时间点内一起运行
- 并发就是几个进程在同一个时间段内,在一个cpu内核上交替运行。由于切换的时间很快,看起来像是在一起运行。
并发主要由切换时间片来实现”同时”运行,并行则是直接利用多核实现多线程的运行,go可以设置使用核数,以发挥多核计算机的能力。
goroutine原理和调度
协程的概念
多进程、多线程提高了系统的并发能力,但是在当今互联网高并发场景下,为每个任务都创建一个线程是不现实的,因为会消耗大量的内存 (进程虚拟内存会占用 4GB [32 位操作系统], 而线程也要大约 4MB)。
我们之前提过,一个线程可以分为内核态线程和用户态线程。一个 “用户态线程” 必须要绑定一个 “内核态线程”,但是 CPU 并不知道有 “用户态线程” 的存在,它只知道它运行的是一个 “内核态线程”,我们再去细化去分类一下,内核线程依然叫 “线程 (thread)”,用户线程叫 “协程 (co-routine)”。
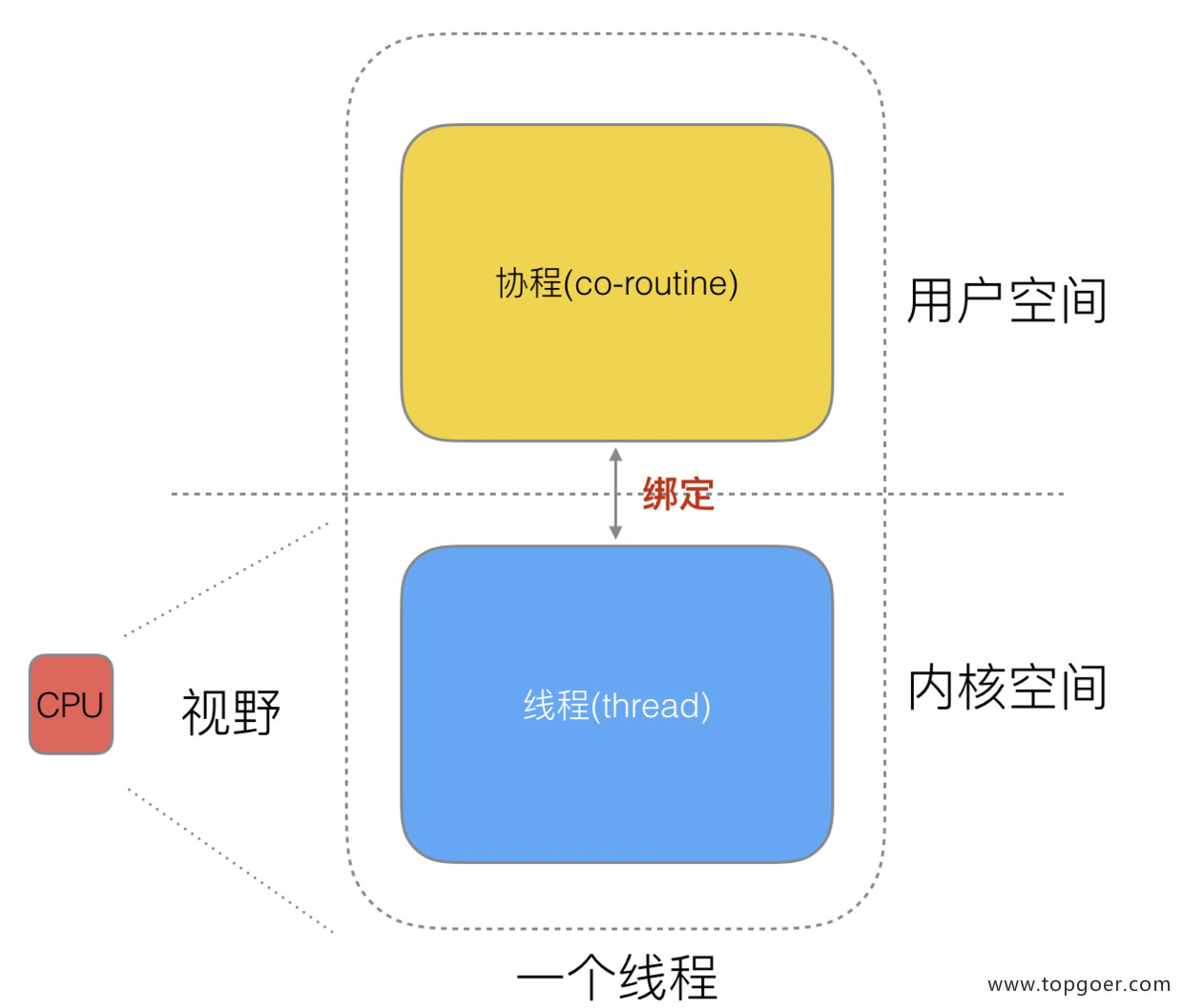
既然一个协程 (co-routine) 可以绑定一个线程 (thread),那么能不能多个协程 (co-routine) 绑定一个或者多个线程 (thread) 上呢。经过演变之后,就有了现在的协程和线程的映射关系:M:N关系。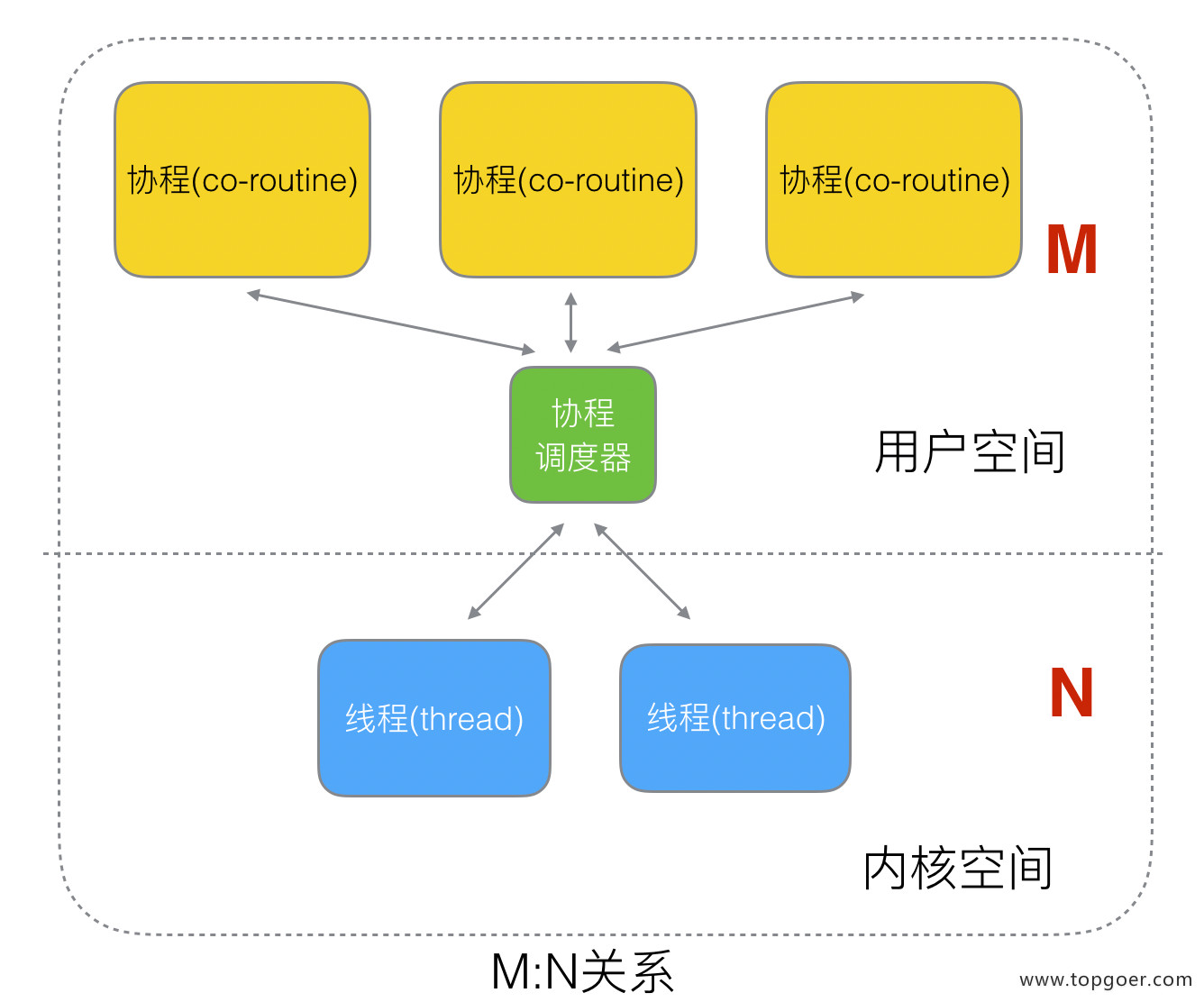
goroutine
Go 为了提供更容易使用的并发方法,使用了 goroutine 和 channel。goroutine 来自协程的概念,让一组可复用的函数运行在一组线程之上,即使有协程阻塞,该线程的其他协程也可以被 runtime 调度,转移到其他可运行的线程上。最关键的是,程序员看不到这些底层的细节,这就降低了编程的难度,提供了更容易的并发。
Go 中,协程被称为 goroutine,它非常轻量,一个 goroutine 只占几 KB,并且这几 KB 就足够 goroutine 运行完,这就能在有限的内存空间内支持大量 goroutine,支持了更多的并发。虽然一个 goroutine 的栈只占几 KB,但实际是可伸缩的,如果需要更多内容,runtime 会自动为 goroutine 分配。
goroutine的概念类似于线程,但 goroutine是由Go的运行时(runtime)调度和管理的。Go程序会智能地将 goroutine 中的任务合理地分配给每个CPU。Go语言之所以被称为现代化的编程语言,就是因为它在语言层面已经内置了调度和上下文切换的机制。
在Go语言编程中你不需要去自己写进程、线程、协程,你的技能包里只有一个技能–goroutine,当你需要让某个任务并发执行的时候,你只需要把这个任务包装成一个函数,开启一个goroutine去执行这个函数就可以了,就是这么简单粗暴。
OS线程(操作系统线程)一般都有固定的栈内存(通常为2MB),一个goroutine的栈在其生命周期开始时只有很小的栈(典型情况下2KB),goroutine的栈不是固定的,他可以按需增大和缩小,goroutine的栈大小限制可以达到1GB,虽然极少会用到这个大,也就是说goroutine的栈是可增长的栈。所以在Go语言中一次创建十万左右的goroutine也是可以的。
单从线程调度讲,Go语言相比起其他语言的优势在于OS线程是由OS内核来调度的,goroutine则是由Go运行时(runtime)自己的调度器调度的,这个调度器使用一个称为m:n调度的技术(复用/调度m个goroutine到n个OS线程)。 其一大特点是goroutine的调度是在用户态下完成的, 不涉及内核态与用户态之间的频繁切换,包括内存的分配与释放,都是在用户态维护着一块大的内存池, 不直接调用系统的malloc函数(除非内存池需要改变),成本比调度OS线程低很多。 另一方面充分利用了多核的硬件资源,近似的把若干goroutine均分在物理线程上, 再加上本身goroutine的超轻量,以上种种保证了go调度方面的性能。
Go语言中使用goroutine非常简单,只需要在调用函数的时候在前面加上go关键字,就可以为一个函数创建一个goroutine。一个goroutine必定对应一个函数,可以创建多个goroutine去执行相同的函数。
GMP调度器
在 Go 中,线程是运行 goroutine 的实体,调度器的功能是把可运行的 goroutine 分配到工作线程上。
Go 设计了新的调度器。
在新调度器中,出列 M (thread) 和 G (goroutine),又引进了 P (Processor)。
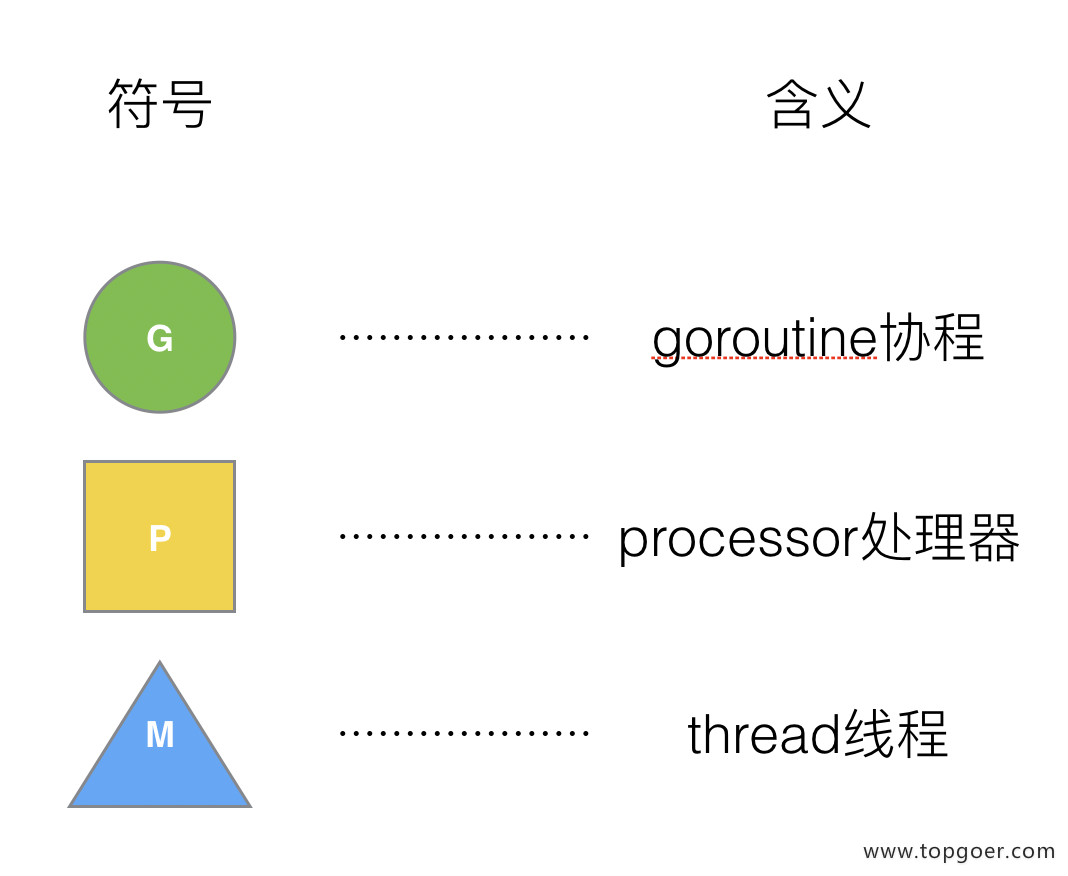
Processor,它包含了运行 goroutine 的资源,如果线程想运行 goroutine,必须先获取 P,P 中还包含了可运行的 G 队列。
(1) GMP 模型
在 Go 中,线程是运行 goroutine 的实体,调度器的功能是把可运行的 goroutine 分配到工作线程上。
GPM是Go语言运行时(runtime)层面的实现,是go语言自己实现的一套调度系统。区别于操作系统调度OS线程。
- G: 很好理解,就是个goroutine的载体,里面除了存放本goroutine信息外 还有与所在P的绑定等信息。
- P:管理着一组goroutine队列,P里面会存储当前goroutine运行的上下文环境(函数指针,堆栈地址及地址边界),P会对自己管理的goroutine队列做一些调度(比如把占用CPU时间较长的goroutine暂停、运行后续的goroutine等等)当自己的队列消费完了就去全局队列里取,如果全局队列里也消费完了会去其他P的队列里抢任务。
- M(machine):是Go运行时(runtime)对操作系统内核线程的虚拟, M与内核线程一般是一一映射的关系, 一个groutine最终是要放到M上执行的;
P与M一般也是一一对应的。他们关系是: P管理着一组G挂载在M上运行。当一个G长久阻塞在一个M上时,runtime会新建一个M,阻塞G所在的P会把其他的G 挂载在新建的M上。当旧的G阻塞完成或者认为其已经死掉时 回收旧的M。
P的个数是通过runtime.GOMAXPROCS设定(最大256),Go1.5版本之后默认为物理线程数。 在并发量大的时候会增加一些P和M,但不会太多,切换太频繁的话得不偿失。
下图是GMP的实现图:
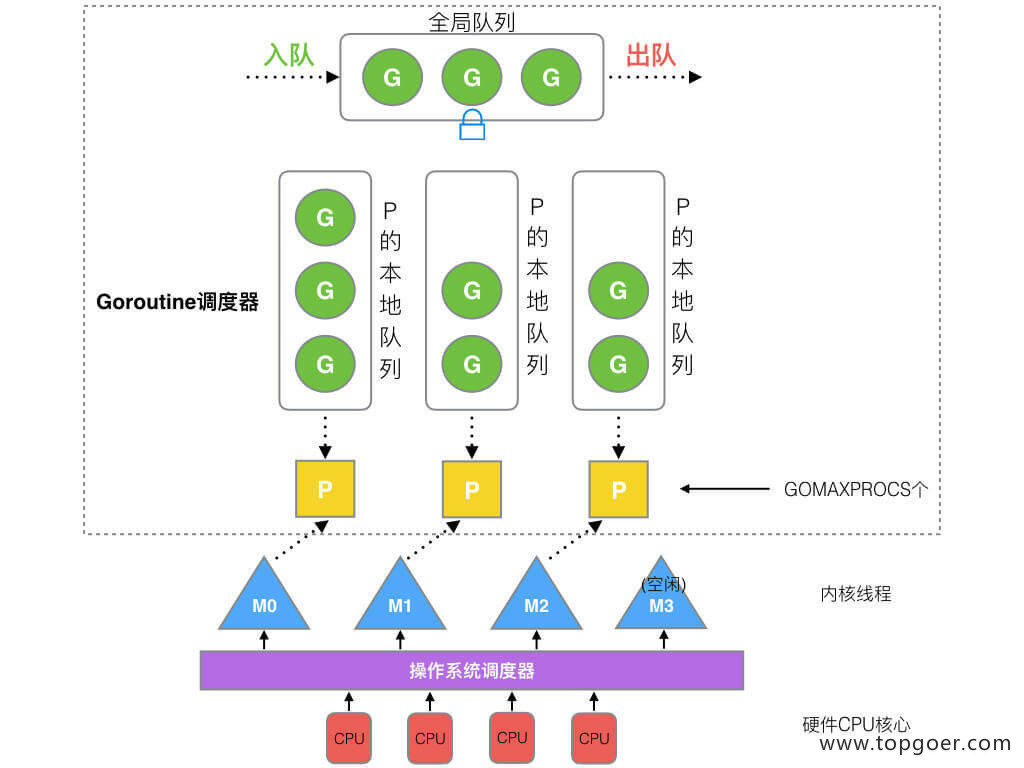
- 全局队列(Global Queue):存放等待运行的 G。
- P 的本地队列:同全局队列类似,存放的也是等待运行的 G,存的数量有限,不超过 256 个。新建 G’时,G’优先加入到 P 的本地队列,如果队列满了,则会把本地队列中一半的 G 移动到全局队列。
- P 列表:所有的 P 都在程序启动时创建,并保存在数组中,最多有 GOMAXPROCS(可配置) 个。
- M:线程想运行任务就得获取 P,从 P 的本地队列获取 G,P 队列为空时,M 也会尝试从全局队列拿一批 G 放到 P 的本地队列,或从其他 P 的本地队列偷一半放到自己 P 的本地队列。M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
Goroutine 调度器和 OS 调度器是通过 M 结合起来的,每个 M 都代表了 1 个内核线程,OS 调度器负责把内核线程分配到 CPU 的核上执行。
(2) 调度器的设计策略
复用线程:避免频繁的创建、销毁线程,而是对线程的复用。
- work stealing 机制
当本线程无可运行的 G 时,尝试从其他线程绑定的 P 偷取 G,而不是销毁线程。
- hand off 机制
当本线程因为 G 进行系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程执行。
利用并行:GOMAXPROCS 设置 P 的数量,最多有 GOMAXPROCS 个线程分布在多个 CPU 上同时运行。GOMAXPROCS 也限制了并发的程度,比如 GOMAXPROCS = 核数/2,则最多利用了一半的 CPU 核进行并行。
抢占:在 coroutine 中要等待一个协程主动让出 CPU 才执行下一个协程,在 Go 中,一个 goroutine 最多占用 CPU 10ms,防止其他 goroutine 被饿死,这就是 goroutine 不同于 coroutine 的一个地方。
全局 G 队列:在新的调度器中依然有全局 G 队列,但功能已经被弱化了,当 M 执行 work stealing 从其他 P 偷不到 G 时,它可以从全局 G 队列获取 G。
(3) go func () 调度流程
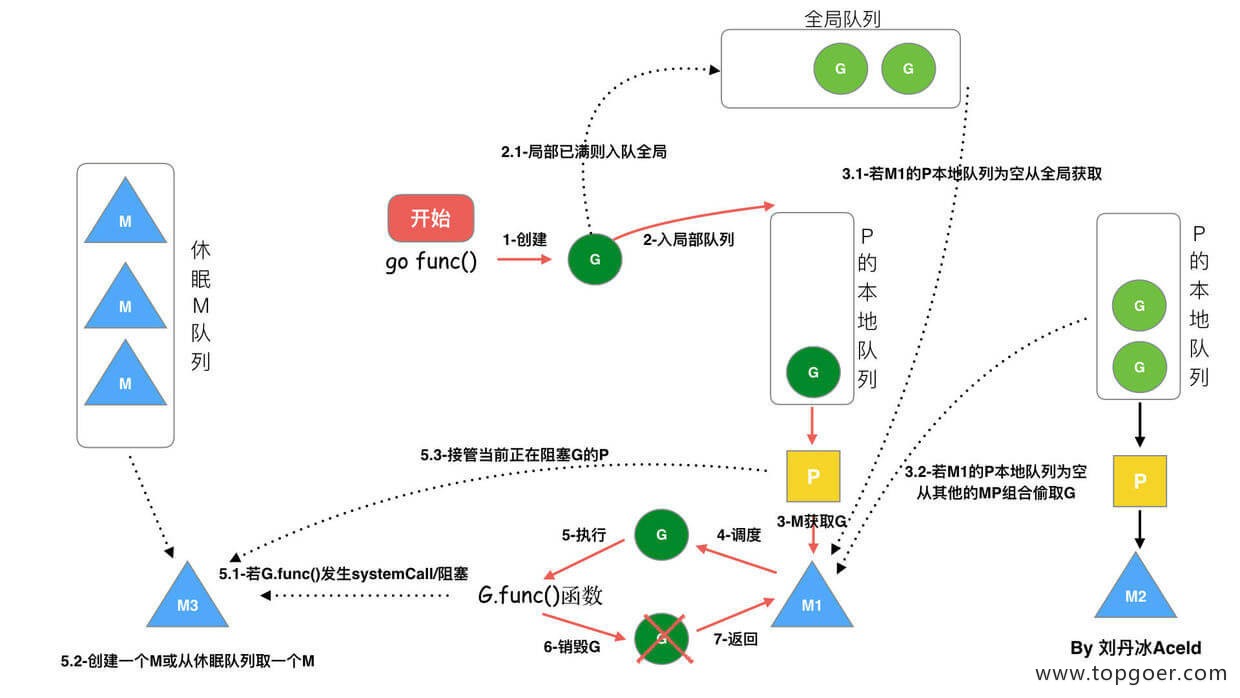 从上图我们可以分析出几个结论:
从上图我们可以分析出几个结论:
1、我们通过 go func () 来创建一个 goroutine;
2、有两个存储 G 的队列,一个是局部调度器 P 的本地队列、一个是全局 G 队列。新创建的 G 会先保存在 P 的本地队列中,如果 P 的本地队列已经满了就会保存在全局的队列中;
3、G 只能运行在 M 中,一个 M 必须持有一个 P,M 与 P 是 1:1 的关系。M 会从 P 的本地队列弹出一个可执行状态的 G 来执行,如果 P 的本地队列为空,就会想其他的 MP 组合偷取一个可执行的 G 来执行;
4、一个 M 调度 G 执行的过程是一个循环机制;
5、当 M 执行某一个 G 时候如果发生了 syscall 或则其余阻塞操作,M 会阻塞,如果当前有一些 G 在执行,runtime 会把这个线程 M 从 P 中摘除 (detach),然后再创建一个新的操作系统的线程 (如果有空闲的线程可用就复用空闲线程) 来服务于这个 P;
6、当 M 系统调用结束时候,这个 G 会尝试获取一个空闲的 P 执行,并放入到这个 P 的本地队列。如果获取不到 P,那么这个线程 M 变成休眠状态, 加入到空闲线程中,然后这个 G 会被放入全局队列中。
依靠通讯的原则
goroutine奉行通过通信来共享内存,而不是共享内存来通信。
单纯地将函数并发执行是没有意义的。函数与函数间需要交换数据才能体现并发执行函数的意义。
虽然可以使用共享内存进行数据交换,但是共享内存在不同的goroutine中容易发生竞态问题。为了保证数据交换的正确性,必须使用互斥量对内存进行加锁,这种做法势必造成性能问题。
Go语言的并发模型是CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
如果说goroutine是Go程序并发的执行体,channel就是它们之间的连接。channel是可以让一个goroutine发送特定值到另一个goroutine的通信机制。
Go 语言中的通道(channel)是一种特殊的类型。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。每一个通道都是一个具体类型的导管,也就是声明channel的时候需要为其指定元素类型。
参考链接:



